
Joining a company is like a light version of marriage —it may be possible to make it work even if you don’t get to know the other person enough ahead of time, and then break it up because of unset expectations, but it sucks. I firmly believe that people should do their research before they decide to join a team. Of course, that doesn’t guarantee a great decision, but it definitely increases those chances substantially.
I always feel like short job descriptions don’t actually describe things well enough for people to make conscious decisions, and so this post is supposed to serve anyone who may join Strigo’s engineering team in the near future.
Note: To get an even better sense of the Why and Who behind Strigo, let’s talk face-to-face :)
What we do
We develop a web application that allows our customers to train their customers, partners and employees on their products.
We provide two types of learning experiences — one with an instructor, and one without. Imagine that Elastic (our first customer) wants to teach their customers how to use Elasticsearch. They will use Strigo to create a course (add slides, videos, exercises, etc..) and then create an environment to learn in. One of the versions of that classroom will provide a learning environment for a single learner. The other will be a virtual classroom (zoom-like, with audio, video, and chat, but with classroom-related capabilities), for all of their learners to join. What’s even nicer is that each learner will get interfaces (web interfaces, terminal, Linux desktop, Windows desktop) to machines we run globally in AWS, right in the browser (we’ve run ~240k instances for learners until today). That’s where the real learning happens, where the learner can actually practice what they’ve been taught. And if the learners need help, instructors can connect to those interfaces from within Strigo, and help them.
There are many challenges to serving our customers and their learners. We need to provide a reliable, performant UX (via globally distributed infrastructure), to make sure they feel as if they are in a real classroom. Everything has to be in a single web app that changes in real-time with very low downtime (it’s a classroom, after all). We also have to feed as much data as we can to our customers. Success for us means significantly improving how people teach and learn software products.
We also support our customers directly, as we believe that engineers have to engage with customers in order to feel their pain and understand what’s important to them. Our system is mission-critical to our customer’s training teams. If there’s a problem and they have learners waiting for them, we can’t really tell them to wait because “Strigo doesn’t work”.
How we do it
Running product development, trying to scale our business, and managing 5 regions-worth of highly-available, distributed infrastructure which support customers like Elastic, Docker, VMware, Sage, NICE, and NCR, isn’t easy.
So how do we do it?
We have the best team, best tools, and best everything. That’s how.
Doesn’t that sound authentic? Let’s try to be real, instead.
- We have a team (10 engineers and two PMs split between two teams, as of the time of writing this post) that has experience in product development and with running complex infrastructure.
- We try to talk in “Business Value” and “Product Value” instead of in “features”. That’s hard to do, but we’ve gotten reasonably good at it at this point. A good reference on how we try to look at this can be found here.
- We provide lots of context, both business-related and product-related so that people can make good decisions.

- We put a strong emphasis on autonomy and mastery, and default to hiring Managers of One. There’s always room to improve, of course, but the principles are there.
- We empower team members to do end-to-end work. Engineers participate in making product value and design decisions and take responsibility for the frontend, backend, docs (most of the time), observability, testing, analytics, and also, depending on the complexity, the infrastructure required to accomplish what they need. They even write the product release notes once in a while, which really puts the nail in it.
- We invest in async communication so that people can consume information and content when it’s comfortable for them. We’re not perfect at it, but we slowly improve and try to balance it with face-to-face in order to move quickly.

- We invest heavily in infrastructure and developer tooling, up to the point where ~100% of our infrastructure in all regions is managed in Terraform (using Atlantis) in a very organized manner. We also have infrastructure tests, EC2 lifecycle hooks and auto-scaling groups which makes deploying infrastructure changes easy and maintainable.

- We use HashiCorp’s Nomad/Consul and Docker to run local, remote, and production environments. It really comes down to a wand (our dev CLI) invocation. A reference article on how we manage remote development environments can be found here (It’s somewhat outdated but accurate enough).
- Almost all of our customer-serving services are written in JavaScript/TypeScript, and our internal ones are in Python, making them manageable and consumable by most engineers out there.
- We default to using third-party services rather than running things ourselves, assuming that no matter how good we get, we will never be able to run these services better than those who’ve made it their mission to do so (for example, our main DB has been running on Mongo Atlas for the last ~4y or so.)
- We don’t focus on anything but impact and improvement. We don’t count work hours, vacation days, story points, etc. Do we know exactly how to measure impact? Of course not. In such a small team, most of it is measured qualitatively, and that’s good enough for the stage we’re in.
- We keep an ongoing burnout discussion, so that the team’s self-awareness is kept in check. We want to ensure people are healthy. Most of us have little kids, which means we have to be careful not to push too hard, while still maintaining momentum.
- Engineers are on-call 3–4d every month and a half or so. Thankfully, one of us is in Australia, which covers Israel’s nighttime. We have very specific alerts that hopefully indicate real problems, to make sure we don’t get alert-fatigued.
- We encourage engineers to innovate on the product level. For example, Strigo’s new A/V grid view was pushed forward by a single engineer.
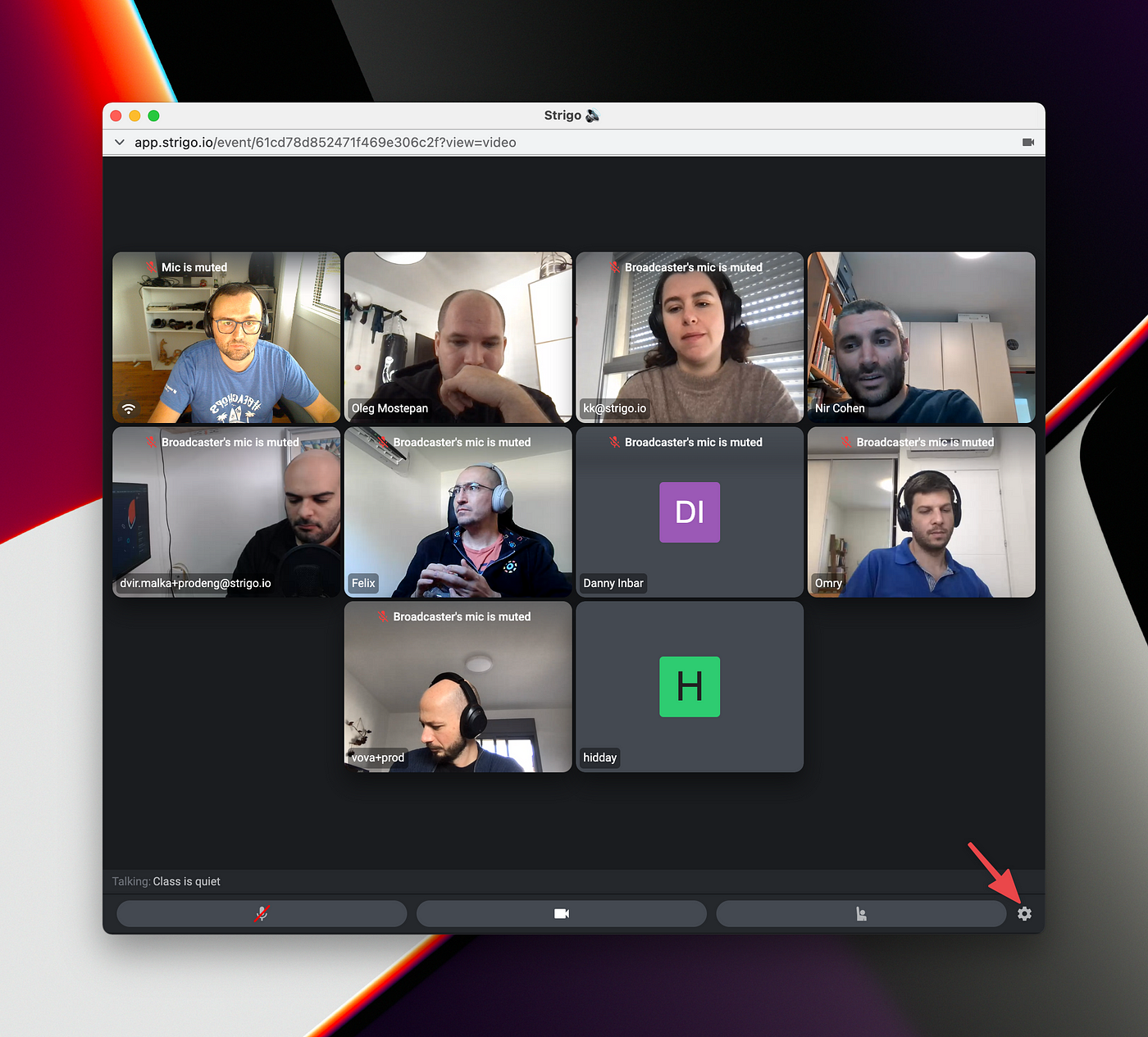
- Between projects, team members work on standalone tech-debt issues and non-critical bugs, so there’s a consistent flow of work around those areas as well.
- We aspire to have tests work for us, not the other way around. We focus on running end-to-end tests on production. In fact, we’ve just introduced canary deployments as part of our CD process, which also runs end-to-end tests on the canary in production before promoting it. We also write unit tests, although quite frankly, we need many more of them.
- We work with Linear (I had to put it here. Finally! A good software project management service!).

- We don’t aim to do what’s “cool”, but rather what’s “right” for our business.
- And most importantly, we never assume that we do everything right. Some things, we do badly. Some other things, we do amazingly well. In general, we know there’s a lot of space for improvement. We try to distribute decisions and responsibilities to people whom we believe will make the best ones, instead of assuming that we already know what’s right.
And, of course, we’re always happy to talk: https://strigo.io/careers



